 Alelle Frequency RtCohort Heterozygosity RtEffective From DtEffective To DtLoad Info SkPopulation Sequence Statistics SkSource Code SkTenant SkTotal Samples NumValid From TsValid To Ts
Alelle Frequency RtCohort Heterozygosity RtEffective From DtEffective To DtLoad Info SkPopulation Sequence Statistics SkSource Code SkTenant SkTotal Samples NumValid From TsValid To Ts
| Atomic Warehouse Model Data Model |
| Description | An association between a population and an allele which can be used to identify the genomic statistical values that are linked to a set of subjects within a cohort. |
| Relationship | |
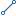 Population Sequence Statistics Detail_Population Sequence Statistics_FK Population Sequence Statistics Detail_Population Sequence Statistics_FK |
|
| Primary Key | |
 Population Sequence Statistics Detail PK Population Sequence Statistics Detail PK |
|
| Dependencies | |
 |
|
| Reverse Dependencies | |
 |
|
| Attribute Details |
Alelle Frequency Rt
| Description | The frequency of the allele in this cohort group. The allele frequency represents the incidence of a gene variant in a population. An allele frequency is calculated by dividing the number of times the allele of interest is observed in a population by the total number of copies of all the alleles at that particular genetic locus in the population. Allele frequencies can be represented as a decimal, a percentage, or a fraction. In a population, allele frequencies are a reflection of genetic diversity. Changes in allele frequencies over time can indicate that genetic drift is occurring or that new mutations have been introduced into the population. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Rate [FLOAT(5)] |
| Is Part Of PrimaryKey | false |
| Is Required | false |
| Is Derived | false |
| Is Surrogate Key | false |
Cohort Heterozygosity Rt
| Description | The heterozygosity or genetic diversity associated with the know Cohort samples. A measure of genetic variation in a population. For example: If an individual carries the gene for black hair and the gene for blond hair, we would say that individual is heterozygous for hair color. Heterozygosity may also refer to the percentage of locations on a chromosome that are heterozygous in an individual. Heterozygosity may also refer to the percentage of locations on a chromosome that are heterozygous in an individual. These locations are called loci (the singular form is locus) and may contain more than one gene. The concept of heterozygosity is frequently extended from an individual to a population in the study of population genetics. Heterozygosity in a population is calculated as follows: 1) Let pi be the frequency p of the allele that has an index number of i for a given locus. The value of pi may therefore range from 0 to 1. 2) Calculate the predicted heterozygosity for a single locus. This is given by the equation 1 - Σpi^2. Since the sum of the terms pi^2 is less than 1, the heterozygosity is a value between 0 and 1. Heterozygosity may therefore be expressed as a percentage. 3) Interpret the significance for the predicted heterozygosity at a single locus. The equation the equation 1 - Σpi^2 shows that the maximum heterozygosity occurs when the alleles for that locus are equally common. For example, for two equally common alleles, the heterozygosity is 1 - Σpi^2 = 1 - (1/2)^2 - (1/2)^2 = 1/2. 4) Calculate the predicted heterozygosity for multiple loci. In this case, we wish to find the average of the sum of the squares of the allele frequencies and subtract it from 1. Thus, the heterozygosity for multiple loci is 1 - 1/mΣΣpi^2. 5) Evaluate the observed heterozygosity of a population for a single locus. We have Ho = Σxi/n where Ho is the observed heterozygosity, n is the population and xi is 0 if the alleles in the individual with index i are equal and 1 if they are different. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Rate [FLOAT(5)] |
| Is Part Of PrimaryKey | false |
| Is Required | false |
| Is Derived | false |
| Is Surrogate Key | false |
Effective From Dt
| Description | Establishes a period where a set of attributes are true according to the business. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Date [DATE] |
| Is Part Of PrimaryKey | false |
| Is Required | true |
| Is Derived | false |
| Is Surrogate Key | false |
Effective To Dt
| Description | Ends a period of effectivity. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Date [DATE] |
| Is Part Of PrimaryKey | false |
| Is Required | false |
| Is Derived | false |
| Is Surrogate Key | false |
Load Info Sk
| Description | The surrogate key of the load information entry describing the details regarding the loading of the row. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Surrogate Key Large [LONG] |
| Is Part Of PrimaryKey | false |
| Is Required | true |
| Is Derived | false |
| Is Surrogate Key | false |
Population Sequence Statistics Sk
| Description | The surrogate key for anchor Cohort Sequence Statistics. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Surrogate Key Large [LONG] |
| Is Part Of PrimaryKey | true |
| Is Required | true |
| Is Derived | false |
| Is Surrogate Key | false |
Source Code Sk
| Description | The origin of the data identifying the actual load source, vendor, manual key entry, or context of the data in a specific row in the database. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Surrogate Key [INTEGER] |
| Is Part Of PrimaryKey | false |
| Is Required | true |
| Is Derived | false |
| Is Surrogate Key | false |
Tenant Sk
| Description | The surrogate key of the entry identifying the legal owner of the data. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Surrogate Key [INTEGER] |
| Is Part Of PrimaryKey | false |
| Is Required | true |
| Is Derived | false |
| Is Surrogate Key | false |
Total Samples Num
| Description | The number of samples analyzed to create these statistics. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Number Integer [INTEGER] |
| Is Part Of PrimaryKey | false |
| Is Required | false |
| Is Derived | false |
| Is Surrogate Key | false |
Valid From Ts
| Description | Establishes a period where a set of attributes are true in the source system. This would be populated with the transaction timestamp and would be used for the snapshot date. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Timestamp [TIMESTAMP] |
| Is Part Of PrimaryKey | true |
| Is Required | true |
| Is Derived | false |
| Is Surrogate Key | false |
Valid To Ts
| Description | Ends a period of validity. |
| Data Type | Standards - Data Domains.ddm/Data Domains/Timestamp [TIMESTAMP] |
| Is Part Of PrimaryKey | false |
| Is Required | false |
| Is Derived | false |
| Is Surrogate Key | false |
| Relationship Details |
Population Sequence Statistics Detail_Population Sequence Statistics_FK
| Is Identifying Relationship | true |
| Child Table | Population Sequence Statistics Detail |
| Child Multiplicity | ZERO_TO_MANY |
| Child Referential Integrity: On Delete | NONE |
| Child Referential Integrity: On Insert | NONE |
| Child Referential Integrity: On Update | NONE |
| Parent Table | Population Sequence Statistics |
| Parent Multiplicity | ONE |
| Parent Referential Integrity: On Delete | NONE |
| Parent Referential Integrity: On Insert | NONE |
| Parent Referential Integrity: On Update | NONE |
| Primary Key Details |
Population Sequence Statistics Detail PK
| Key Attribute | Population Sequence Statistics Sk |
| Key Attribute | Valid From Ts |
| Atomic Warehouse Model Data Model |